
Instant Access to Best-in-Class Models, All in One Place
Instant Access to Best-in-Class Models, All in One Place
 DeepSeek-V4-Flash
DeepSeek-V4-Flash 1M-token ultra-long context window, with a smaller parameter count and reduced activations, enabling faster and more cost-effective API serving.
_1.svg) GLM-5.1
GLM-5.1GLM-5.1 is the latest flagship model from Zhipu AI, featuring significantly enhanced coding capabilities and long-running task performance. In terms of overall capability and coding proficiency, it is comparable to Claude Opus 4.6. It demonstrates strong performance in extended task orchestration, complex engineering and optimization, and real-world development scenarios, making it an ideal foundation for building autonomous agents and long-horizon coding agents.
 DeepSeek-V3.2
DeepSeek-V3.2DeepSeek-V3.2 delivers significantly enhanced inference accuracy and contextual understanding, with strong performance in complex logical reasoning and multi-turn dialogue, while balancing response speed with semantic accuracy.
GLM-5GLM-5 delivers marked gains over GLM-4.7 across academic benchmarks, with SOTA reasoning, coding & Agent performance among global open-source models, closing the gap with top closed-source models.
DeepSeek-V3.1DeepSeek-V3.1 was developed by post-training the DeepSeek-V3.1-Base model
DeepSeek-R1-0528DeepSeek-R1-0528 is a reasoning-focused model optimized for complex problem solving, featuring deeper reasoning chains and significantly reduced hallucination rates.
DeepSeek-V4-Flash 1M-token ultra-long context window, with a smaller parameter count and reduced activations, enabling faster and more cost-effective API serving.
Recommended Models by Use Case
Recommended Models by Use Case
- AI Search
- Code Generation
- User Profiling
- Translation
- Prompt Optimization
Accurately understands user intent behind complex queries and provides comprehensive answers with cited reference links.
Semantic understanding: Identifies real user intent based on the context, rather than just keywords.
Retrieval Augmented Generation (RAG): Provides authoritative, traceable answers by combining enterprise knowledge bases and documentation.
Multimodal: Supports integrated search that combines text, images, and videos.

1M-token ultra-long context window, with a smaller parameter count and reduced activations, enabling faster and more cost-effective API serving.
Ultra-long context window for handling extensive inputs
Low footprint and high efficiency – the most cost-effective choice for developers and enterprises
Input: USD 0.135 per M tokens
Output: USD 0.27 per M tokens
A remarkable balance between computational efficiency and exceptional reasoning and agentic capabilities
Excels at decomposing ambiguous user intent and planning search steps, ideal as the core reasoning engine of AI search agents.
Input: USD 0.27 per M tokens
Output: USD 0.404 per M tokens
Powerful chain-of-thought capabilities, able to perform in-depth logical verification and integration of fragmented search results
Transparent inference/reasoning process, ideal for retrieval as a long-context model
Input: USD 0.539 per M tokens
Output: USD 2.156 per M tokens
Automatically generate accurate and executable program code based on requirement descriptions or comments
High efficiency for productivity improvement: Replace manual writing of basic codes to significantly shorten development cycles and labor costs
Accurate and applicable: Generate code that strictly conforms to requirements and comment logic, providing directly runnable results and reducing syntax errors
Accessible compatibility: Support natural language demand input to lower the technical threshold for non-professional developers

GLM-5.1: Global top-tier general & coding performance, on par with Claude Opus 4.6, top-ranked in key benchmarks.
Massively Enhanced Code Capabilities, Dramatic Leap in Long-Horizon Task Performance
Input: USD 0.809 per M tokens
Output: USD 3.235 per M tokens
Input: USD 1.078 per M tokens
Output: USD 3.774 per M tokens
Digs deep into user data and automatically creates accurate user profiles.
Data convergence: Integrates multi-source data to build unified user profiles from fragmented information.
Real-time update: Dynamically updates user tags and supports flexible segmentation and comparative analysis.
Insight-to-value: Integrates with recommendation and marketing systems to improve user conversion.
1M-token ultra-long context window, with a smaller parameter count and reduced activations, enabling faster and more cost-effective API serving.
Ultra-long context window for handling extensive inputs
Low footprint and high efficiency – the most cost-effective choice for developers and enterprises
Input: USD 0.135 per M tokens
Output: USD 0.27 per M tokens
Delivers stable performance in real-time data processing and basic analytics, supporting rapid user data processing and initial profile generation.
Ideal for real-time user profiling, and capable of rapidly processing large amounts of user data and generating insights to support real-time decision-making.
Input: USD 0.539 / M tokens
Output: USD 1.617 / M tokens
Powerful chain-of-thought capabilities, able to perform in-depth logical verification and integration of fragmented search results
Transparent inference/reasoning process, ideal for retrieval as a long-context model
Input: USD 0.539 per M tokens
Output: USD 2.156 per M tokens
Supports accurate, fluent, and context-aware translations across multiple languages, breaking down language barriers.
Context-aware: Produces accurate translations based on context, avoiding literal or word-for-word output.
Multilingual: Supports bidirectional translation across multiple languages for global users.
Fluent & natural: Delivers professional, highly readable translations.
1M-token ultra-long context window, with a smaller parameter count and reduced activations, enabling faster and more cost-effective API serving.
Ultra-long context window for handling extensive inputs
Low footprint and high efficiency – the most cost-effective choice for developers and enterprises
Input: USD 0.135 per M tokens
Output: USD 0.27 per M tokens
Delivers stable performance in real-time data processing and basic analytics, supporting rapid user data processing and initial profile generation.
Ideal for real-time user profiling, and capable of rapidly processing large amounts of user data and generating insights to support real-time decision-making.
Input: USD 0.539 / M tokens
Output: USD 1.617 / M tokens
A remarkable balance between computational efficiency and exceptional reasoning and agentic capabilities
Excels at decomposing ambiguous user intent and planning search steps, ideal as the core reasoning engine of AI search agents.
Input: USD 0.27 per M tokens
Output: USD 0.404 per M tokens
Refines user instructions to guide LLMs to generate more accurate responses at lower cost.
Lower cost: Removes redundancy from user instructions to reduce unnecessary computations for LLMs, lowering inference costs.
Higher efficiency: Rewrites user instructions in ways that are easier for LLMs to understand, significantly improving the accuracy of AI responses.
Lower barrier to entry: Converts vague instructions from average users into efficient inputs, enhancing user experience.
1M-token ultra-long context window, with a smaller parameter count and reduced activations, enabling faster and more cost-effective API serving.
Ultra-long context window for handling extensive inputs
Low footprint and high efficiency – the most cost-effective choice for developers and enterprises
Input: USD 0.135 per M tokens
Output: USD 0.27 per M tokens
A remarkable balance between computational efficiency and exceptional reasoning and agentic capabilities
Excels at decomposing ambiguous user intent and planning search steps, ideal as the core reasoning engine of AI search agents.
Input: USD 0.27 per M tokens
Output: USD 0.404 per M tokens
Delivers stable performance in real-time data processing and basic analytics, supporting rapid user data processing and initial profile generation.
Ideal for real-time user profiling, and capable of rapidly processing large amounts of user data and generating insights to support real-time decision-making.
Input: USD 0.539 / M tokens
Output: USD 1.617 / M tokens
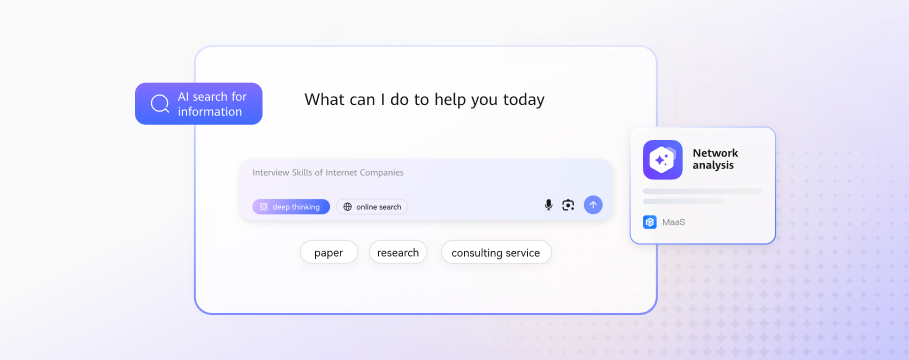
Accurately understands user intent behind complex queries and provides comprehensive answers with cited reference links.
Semantic understanding: Identifies real user intent based on the context, rather than just keywords.
Retrieval Augmented Generation (RAG): Provides authoritative, traceable answers by combining enterprise knowledge bases and documentation.
Multimodal: Supports integrated search that combines text, images, and videos.

Automatically generate accurate and executable program code based on requirement descriptions or comments
High efficiency for productivity improvement: Replace manual writing of basic codes to significantly shorten development cycles and labor costs
Accurate and applicable: Generate code that strictly conforms to requirements and comment logic, providing directly runnable results and reducing syntax errors
Accessible compatibility: Support natural language demand input to lower the technical threshold for non-professional developers

Digs deep into user data and automatically creates accurate user profiles.
Data convergence: Integrates multi-source data to build unified user profiles from fragmented information.
Real-time update: Dynamically updates user tags and supports flexible segmentation and comparative analysis.
Insight-to-value: Integrates with recommendation and marketing systems to improve user conversion.

Supports accurate, fluent, and context-aware translations across multiple languages, breaking down language barriers.
Context-aware: Produces accurate translations based on context, avoiding literal or word-for-word output.
Multilingual: Supports bidirectional translation across multiple languages for global users.
Fluent & natural: Delivers professional, highly readable translations.
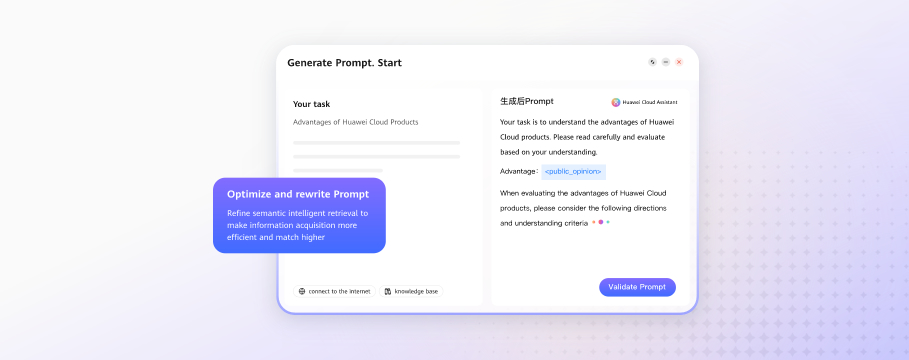
Refines user instructions to guide LLMs to generate more accurate responses at lower cost.
Lower cost: Removes redundancy from user instructions to reduce unnecessary computations for LLMs, lowering inference costs.
Higher efficiency: Rewrites user instructions in ways that are easier for LLMs to understand, significantly improving the accuracy of AI responses.
Lower barrier to entry: Converts vague instructions from average users into efficient inputs, enhancing user experience.
Why Huawei Cloud MaaS?
為什么選擇MaaS服務(wù)
4x performance
Powered by CloudMatrix
Proprietary acceleration engine
Low-latency experience
Privacy protection
Never using customer data for model training
High-quality models
DeepSeek | GLM, etc.
4x performance
Powered by CloudMatrix
Proprietary acceleration engine
Low-latency experience
Privacy protection
Never using customer data for model training
High-quality models
DeepSeek | GLM, etc.
You can choose HTTPS to import models into MaaS to ensure secure data transmission.
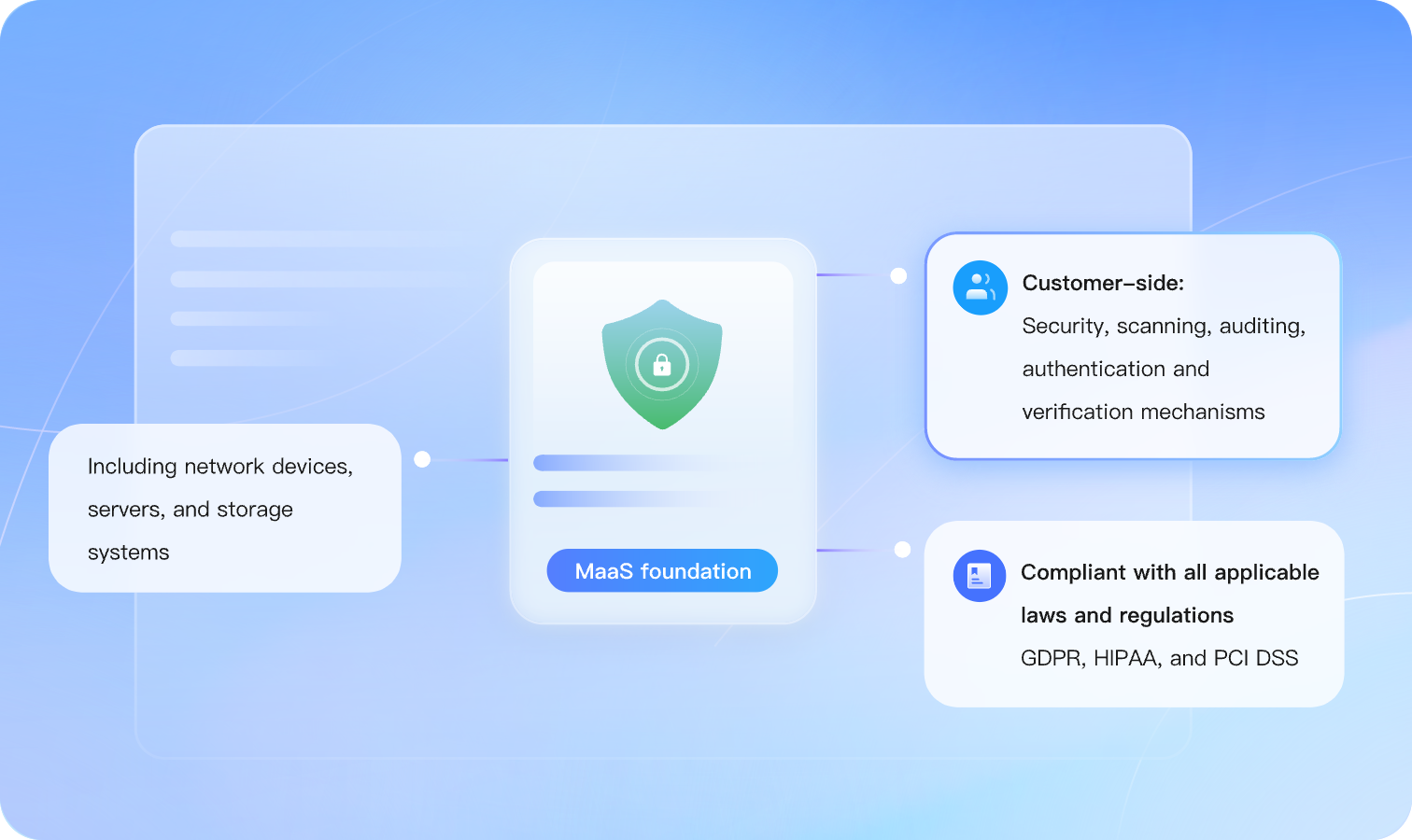
Operation records (traces) on all your cloud resources can be collected, stored, and queried, and used for security analysis, compliance auditing, resource tracking, and troubleshooting.
